


Apple releases OpenELM language models for work without the Internet
Apple has introduced a new series of OpenELM language models designed to work locally on devices without the need to connect to cloud services. The series includes eight models of different sizes and types, which range from 270 million to 3 billion parameters.
These models have been trained on huge public datasets, including 1.8 trillion tokens from resources such as Reddit, Wikipedia, and arXiv.org. Thanks to a high degree of optimization, OpenELM models are able to run on regular laptops and even some smartphones, as demonstrated on devices such as Intel i9 and RTX 4090 PCs and MacBook Pro with M2 Max chip.
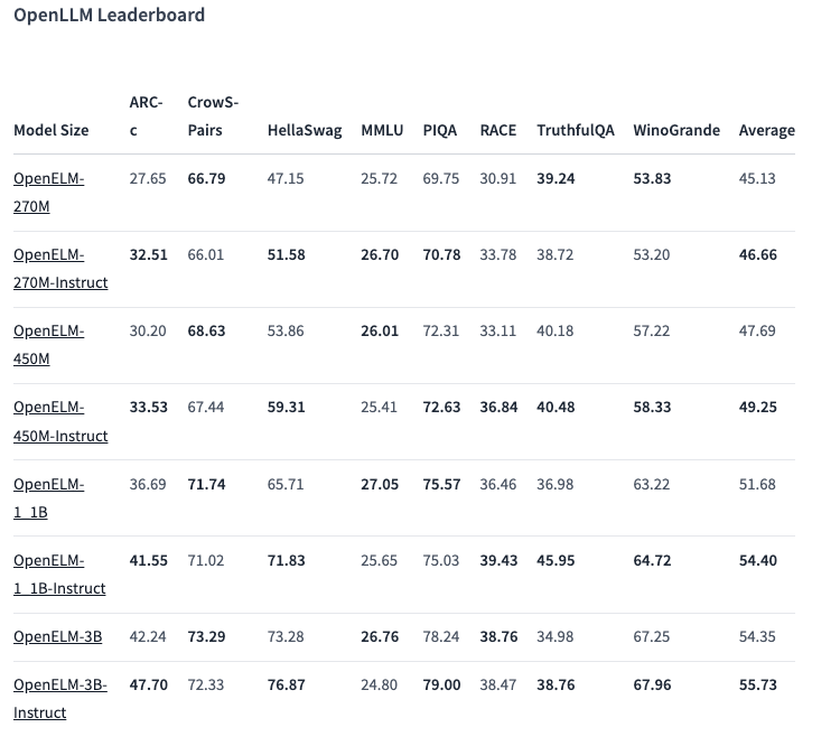
One of the selected options, a model with 450 million parameters, with instructions, showed excellent results. The OpenELM-1.1B model with 1.1 billion parameters proved to be 2.36% more efficient than the similar GPT model, OLMo, while using half as much training data.
In the ARC-C benchmark, designed to test knowledge and logical reasoning, the pre-trained version of OpenELM-3B showed an accuracy of 42.24%. On other tests, such as MMLU and HellaSwag, the model scored 26.76% and 73.28%, respectively.
Apple has also published the OpenELM source code on the Hugging Face platform under an open license, providing access to trained models, benchmarks, and instructions for working with these models. However, the company warns that the models may produce incorrect, malicious, or unacceptable responses due to the lack of security guarantees.